이 글은 체계적인 정리보다는 메모에 가깝습니다.
해당 논문에 대해 이야기 나누고 싶으시다면 언제든지 환영합니다.
Mass-Editing Memory In a Transformer
Meng et al., 2022
https://arxiv.org/abs/2210.07229
Mass-Editing Memory in a Transformer
Recent work has shown exciting promise in updating large language models with new memories, so as to replace obsolete information or add specialized knowledge. However, this line of work is predominantly limited to updating single associations. We develop
arxiv.org
요약
- MEMIT은 LLM의 특정 layer들을 수정하여 factual memory를 수정하는 방법론이다.
- 다른 방법론에 비해 100배 이상의 사이즈로 실험을 진행하였다.
- relation의 종류에 따라 어려움을 겪는 경우가 존재함을 발견하였다.
- 본 논문은 (s, r, o) 형태로 존재하는 factual memory에 대한 수정만을 다루었다.
Introduction
최근 ‘constrained fine-tuning’, ‘hypernetwork knowledge editing’, ‘rank-one model editing’과 같은 기법들이 knowledge-editing 방법론으로 사용되었다.
그러나 해당 기법들은 single-edit에 대해 다루는 경우가 많으며, 많아도 75회 이상의 editing을 다루지 않았다.
따라서 수백, 수천개의 업데이트를 동시에 진행하는 것에 대한 연구가 필요하다.
논문은 MEMIT이라는 scalable multi-layer update algorithm을 사용하여 to insert new memories, explicitly calculated parameter update를 이용하고자 한다.
‘’MEMIT can scale and successfully store thousands of memories in bulk’’
논문은 true facts 주입, counterfactuals, 27 specific relations, different mixed sets of memories 등의 동작을 분석한다.
다른 knowledge-editing 논문들과 유사하게
- generalization
- specificity
- fluency
의 관점에서 모델의 robustness를 측정하였고
baselines은 ‘rank-one(MEND)’, ‘hypernetwork’, ‘fine-tuning’ 으로 이루어졌다.
Related work
Language models as knowledge bases
그동안 LLM을 knowledge-base로 directly 사용하는 것이 많이 제안되었다.
그러나, LLM의 knowledge는 implicit하고 응답 또한 구체적 phrasings of the prompt에 민감하다.
그리고 무엇보다 catalog, add, update 하는 것은 아직도 어려운 문제이다.
Direct model editing
해당 논문의 목적은 ‘localize and understand the internal mechanisms within LLMs’이다.
최근 연구를 통해 transformer의 MLP layer가 key-value memory로 사용된다는 것이 밝혀졌고
(T-patcher에서는 마지막 FFN이 해당 역할을 한다고 이야기했음, MLP module이라는 점에서 유사한 것 같음)
따라서, 이 논문은 그러한 기능에 초점을 맞추었다.
또한, single-edit과는 다르게 sequence of layers를 수정하여, 수천개의 수정을 동시에 진행하도록 개발했다.
Preliminaries

(s, r, o) 형태의 문제에 대해 r을 잘 수정하여 s를 원하는 o와 연결하는 것을 목적으로 진행한다.
MEMIT의 목적은 autoregressive LLM의 파라미터에 저장된 factual associations(r)를 수정하는 것이다.
해당 부분을 이해하기 위해 우선 몇가지 notation이 있다.
D-layer의 transformer decoder G에 의한 Conditional token distribution은 아래와 같이 정의된다.

여기서 $h_{[E]}^{D}$는 transformer의 hidden state representation이다.
위의 식은 디코더에 [1] token 부터 [E] token 까지의 순서로 generation이 진행되었을 때 모델이 다음 토큰으로 내뱉을 [t] token 에 대한 확률분포로 해석하면 되고
해당 분포는 마지막(D-layer)의 결과물인 hidden state representation에 weight matrix $W_y$를 행렬곱한 후(Fully Connected) softmax를 씌운 결과물로 보면 된다.
hidden state representation은 구체적으로 아래의 iteration을 거치며 전개된다.
( $h_{[t]}^0(x)$ = embedding of token $x_{[t]}$, $\gamma$ = layernorm )

해당 수식은 크게 (1) $h_{[t]}^{l-1}(x)$, (2) $a_{[t]}^l(x)$ (3) $m_{[t]}^l(x)$ 의 세 개의 구조로 분리해 생각해볼 수 있고
구체적으로 뜯어보기 위해 우선 GPT의 디테일한 구조에 대해 살펴볼 필요가 있는데 우선 아래의 기본적인 GPT 내의 transformer block 구조를 보면

이전 block의 output인, 본 논문의 notation에 따라 $h_{[t]}^{l-1}$이 input으로 block에 들어오면
1차적으로 layernorm($\gamma$)를 거치고 attention block을 통과한 후 기존의 입력과 residual 하게 더한다.
(2번구조 + 1번구조)
해당 결과물은 다시 layernorm($\gamma$)를 거치고 $W_{in}$과 곱해진 후 Gelu 통과, 다시 $W_{out}$과 곱해진 후 다시 방금 전 결과물과 residual 하게 더한다
(3번구조 + 1번구조)
해당 구조는 아래와 같은 iteration으로 해석이 가능하다. (아래는 MEMIT 논문과 동일 저자 선행 논문인 ROME의 notation)

<위는 ROME의 notation>


이제 수식을 다시 살펴보면 위의 설명과 조금 다른 부분이 있는데, 위의 GPT 구조에서는 분명 attention block을 통과한 결과물을 MLP layer의 input으로 넣었지만 본 수식에서는 단순히 더하는 형태로 묘사된 것이다.
이는 해당 논문이 GPT-J를 기반으로 작성되었기 때문이며, 실제 GPT-J와 비교해보면 아래와 같이 attention block과 MLP layer(Feed forward network)이 병렬적으로 연결되어 있음을 확인할 수 있다.

다음은 논문의 목적인 editing에 대한 정의이다.

s, r, o는 각각 subejct s, relation r, object o로 정의되며, 예시로 (s = Michael Jordan, r = plays sport, o = basketball)이 있다.
논문의 목적은 따라서 주어(subject)와 관계(relation)이 같지만, 목적어(o)는 다른 (s, r, o) 집합이 존재하지 않도록 하는 것이다.(no conflicting requests)
평가의 관점에서는
- Generalization
- rephrasing 구문을 맞추는 것
- Specificity
- 다른 정보를 해치지 않는 것(locality)
- Fluency
- disfluent한 문장을 만들지 않는 것
으로 정의하였다.
Method
MEMIT은 causal mediation analysis를 사용해 트랜스포머 mechanism에 정보를 주입한다.(Meng et al., 2022)

논문에서는 가장 마지막으로 들어온 subject token S에 대하여 mediate factual association recall 하는 critical MLP layer $R$을 발견하였고, MEMIT은 두가지 동작으로 작동한다고 한다.
(i) critical layer로 하여금 저장하고자 하는 vector association을 계산하는 것
(ii) 각 layer $l \in R$에 대하여 원하는 emory의 일부를 저장하는것
stored association을 edit하는 방식을 위의 그림과 함께 보면
(a) 앞부분의 attention module은 last subject token S(Jordan)에 대해 vector representation으로 변환
(b) critical layer 집합 $R$에 해당하는( 초록색 부분 ) 에서는 정보를 encoding하고 residual stream에 저장
(c) 해당 hidden states는 후에 output을 생성할 때 읽음
(d) MEMIT은 결과적으로 critical MLP에 저장된 연결 부분을 수정한다.
그림(d)를 조금 디테일하게 보면 critical MLP의 Gelu를 통과한 $k_i^l$은 $W_{out}^l$과 곱해진 후 $m_i^l$이 되는데
해당 과정에서 $k$는 subject 의 key로, $m$은 memorized value로 작동하므로
우리가 새로운 정보(s, r, o)를 넣고자 한다면 s가 저장되는 방식인 $W_{out}^l$을 수정함으로써 s와 o를 새롭게 연결하여 저장하는 것이다.
일반적으로 아는 query, key, value의 관점에서 조금 더 쉽게 풀면(위의 key랑은 다름), 나중에 plays(query)가 와서 $m_i^l$(Jordan이 저장된 key)에게 물어봤을 때 기존의 key가 ‘basketball’로 연결했다면 $m_i^l$의 응답이 ‘baseball’이 될 수 있도록 key를 바꾸고 싶은데
해당 key는 input $k_i^l$에 대하여 $W_{out}^lk_i^l$의 형태로 저장되기 때문에 $W_{out}^l$을 학습시켜 key를 바꾸는 것이다.
Causal Traces
그렇다면 위에서 이야기한 critical MLP layer $R$이 어디인지, 구체적으로 어떤 위치에 정보가 저장되는지 확인 할 필요가 있다.
해당 과정을 논문에서는 Causal Traces 라고 하였으며,
구체적인 과정을 이해하기 위해서는 동일 저자의 선행 논문 ‘Locating and Editing Factual Associations in GPT(ROME)’을 찾아보면 나와있는데
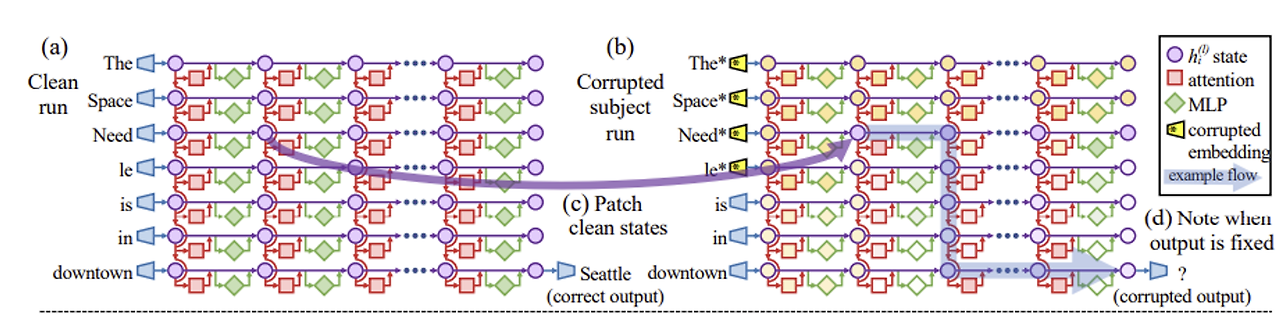
ROME에서는 다음과 같은 과정을 거쳐 causal effect를 추정한다고 한다. (ROME의 그림은 GPT-2 XL)
- 올바른 답이 나오는 예시에 대해 1회 진행하며 각 state를 모두 저장해둔다.
- 그 다음 subject token의 embedding을 임의로 변경하여 전혀 다른 output이 발생하도록 한다.
- 1번에서 계산되었던 각 state들의 값을 2번의 state들에 각각 넣어보며 기존의 output이 나올 확률을 계산하며
- 그 결과를 전체 데이터에 대해 평균낸 값을 AIE(Average Indirect Effect)라고 한다.
위의 세 과정을 거치며 계산된 AIE를 통해 어떤 state가 해당 subject에 대한 정보를 담고 있는지 알 수 있다. (아래는 본 논문의 히트맵)

causal effect는 다음과 같이 나타났으며 MLP layer는 Last subject token의 앞부분 layer에서, attention layer는 last token의 뒷부분 layer에서 전체 추론에 큰 영향을 미친다는 것을 알 수 있다.
Causal effects with a modified computation graph
다음 실험은 ablation study와 비슷하며 이도 ROME의 실험을 가져와 유사하게 진행하였다.

ROME에서는 다음과 같이 각 module의 중요성을 탐색한다.
- 1회 전개하며 state 저장
- 위와 동일하게 input을 붕괴시키고 원래 hidden state의 AIE 계산, attention module을 고정하고 AIE 계산, MLP module을 고정한 후 AIE 계산
똑같이 진행하면 아래와 같은 표가 생성된다.

hidden state의 AIE(보라)와 attention module 제거 후 AIE(빨강)은 크게 차이가 없지만,
MLP module 제거 후 AIE(초록)과 비교해보면 2가지를 확인할 수 있을 것이다.
- MLP 모듈이 subject token의 내용을 저장할 때 큰 영향을 미친다.
- 해당 영향은 앞부분~중간부분 layer에서 강하게 진행된다.
최종적으로 위의 두 실험을 통해 GPT-J 모델은 $R = {3,4,5,6,7,8}$ 의 MLP layer를 critical MLP layer로 정의하여 논문을 전개하였다.(ROME에서는 single layer만을 선택하였지만, 본 논문에서는 range로 설정하여 더 많은 수정을 의도하였다.)
Update
우선 $h_i^L$을 GPT-J에 있어 서로 단순히 더해지는 형태이므로 아래와 같이 unrolling을 진행한다.

추가로 기존의 notation도 단축하여
$W_0\triangleq W_{out}^l$ , $k_i \triangleq k_i^l$ , $m_i \triangleq m_i^l$로 표현한다.
또한, 여러 데이터를 동시에 업데이트하기 위해 새로운 notation을 추가하여
$K_0 = [k_1 | k_2 | ... | k_n], M_0 = [m_1|m_2|...|m_n]$과 같이 정의한다.

Updating Single linear associative memory
우선 지금까지의 전개에 따라 기존 $W_0$ matrix를 아래와 같이 표현이 가능하다.
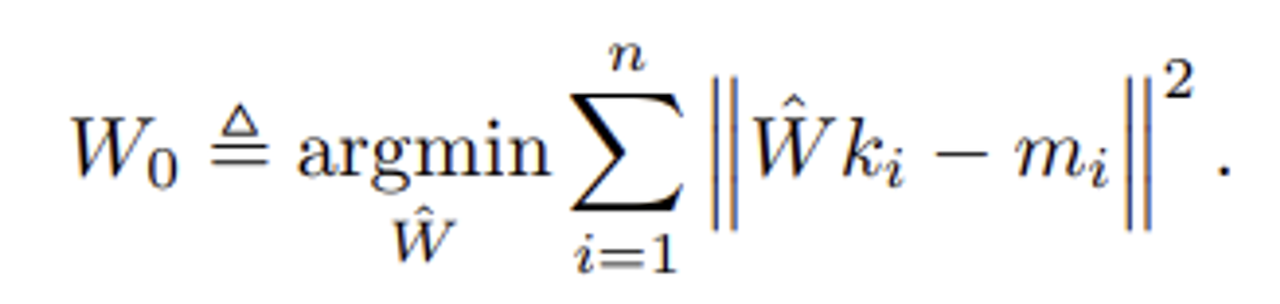
이제 여기서 argmin 오른쪽을 목적함수로 정의하고 minimal squared error의 문제로 Normal euqtion을 푼다면 아래와 같이 $W_0$를 계산 가능하다.

우리가 새롭게 업데이트 하고자하는 $W_1$은 아래와 같이 정의가 가능하다.(좌측은 기존의 데이터 최적화, 우측은 새로운 데이터 최적화)

여기서 $W_1 = W_0 + \Delta$ 로 표현이 가능하며 우리의 목표는 이 $\Delta$을 계산하는 것이다.
앞과 동일하게 normal equation을 적용하여 전개하면

다음과 같이 전개가 가능하고, 여기서 $W_0$의 최적화 식을 제거하면
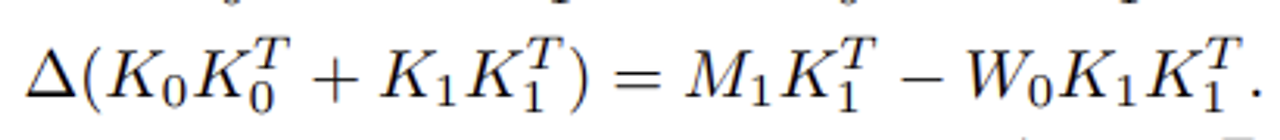
다음과 같이 정리가 된다.
위 식을 깔끔하게 정리하기 위해 2가지 식을 의미에 맞게 정의한다.

$C_0$는 pre-existing keys, 즉 사전에 학습된 key의 covariance 역할을 한다.

$R$은 기존의 $W_0$를 이용해 새로운 데이터 $K_1$을 전개했을 때 발생하는 residual error이다.
따라서, 최종 $W$의 변화량 $\Delta$은 아래와 같다.

여기서 문제가 발생하는데, 우리는 해당 모델이 pretrain한 데이터를 완벽하게 알지 못하기 때문에 $K_0, M_0$을 계산할 수 없고, 해당 이유로 $C_0$ 또한 계산할 수 없다는 것이다.
따라서, 본 논문에서는 실험적으로 random한 데이터들을(100,000 samples) 사용한 기댓값을 통해 $C_0$을 역추정하였다.
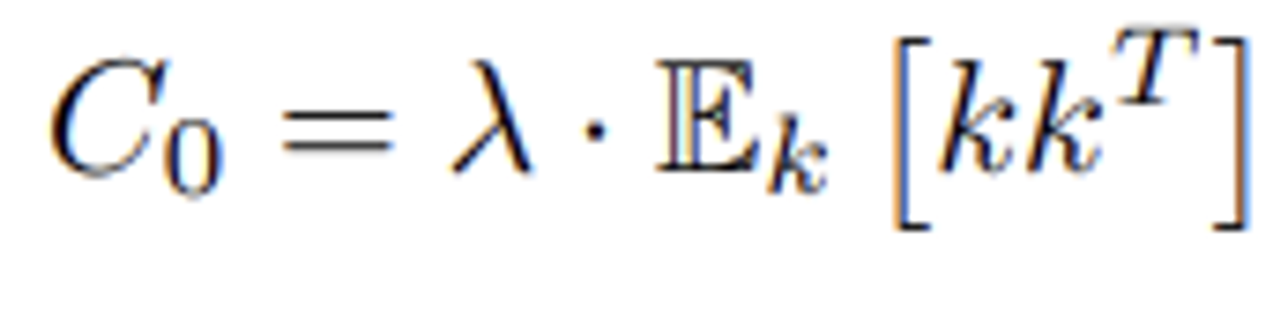
여기서 $\lambda$는 pretrain 데이터와 새로 입력할 데이터의 가중치 비율로, $\lambda = 1.5 \times 10^4$을 사용하였다.
Updating multiple layers
기존 연구 결과 모델 editing에서의 robustness는 변화된 parameter의 크기가 작을수록 향상된다는 것이 증명되었다.(Zhu et al., 2020)
따라서, 이 논문에서는 모델 업데이트를 mediating layers에 분산시켜 진행하였다.
우선 target layer를 $L \triangleq max(R)$로 정의하였다.(end of the mediating layers)
각각의 edit$(s_i, r_i, o_i) \in E$ 에 대하여
(i) $h_i^L$을 대신할 $z_i$를 계산, 이 때 $\delta_i \triangleq z_i - h_i^L$ 을 더하는 형태를 취한다.
(ii) 해당 $z_i$를 만족할 수 있도록 MLP layer 수정

조금 더 구체적으로 전개하면
(i)Computing $z_i$
우선 gradient descent를 통해 아래와 같이 $\delta$를 계산한다.

해당 식을 풀어서 설명하면 $\delta_i$ 는 기존의 decoder $G$의 $h_i^L$을 수정하여 원하는 object $o_i$가 나올 확률을 가장 높게 만들어주는 값이라고 정의할 수 있으며
이때 prompt는 ${x_j \oplus p(s_i, r_i)}$라고 할 수 있고 $x_j$는 generalization을 위해 사용되는 random prefixes(접두사)라고 할 수 있다.
또한 이러한 과정(기존 h와 새로운 z사이를 연결하는 것)을 hooking이라고 이야기한다.
(ii) Spreading $z_i - h_i^L$ over layers
이제 논문의 새로운 목적은 아래와 같다.
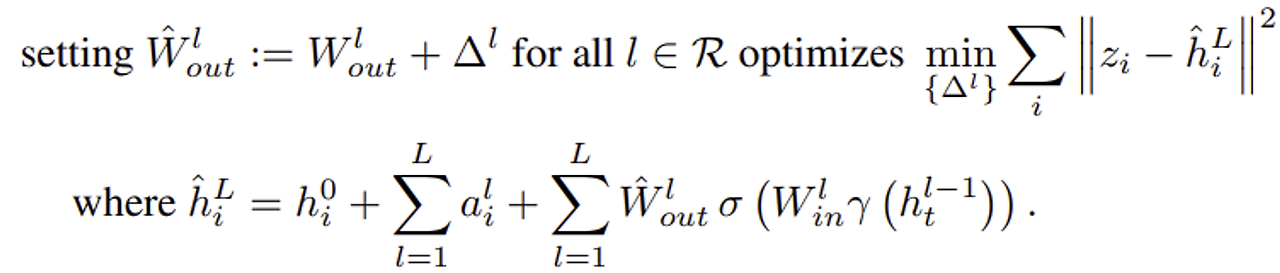
각각의 layer에 필요한 $\Delta^l$를 더하는 것이다.
이때 한 layer를 수정하면 뒤의 layer에도 영향을 미치기 때문에 앞의 layer부터 iterative하게 오름차순으로 변경을 진행한다.
이제 k를 아래와 같이 계산하고

최종적으로 m에 residual을 더해준다. 해당 과정은 target layer(수정할 마지막 MLP layer)에서 멀어질 수록 영향력을 낮춘다.

최종적으로 아래와 같이 알고리즘이 구성된다.

Experiments
사용 모델 : GPT-J (6B), GPT-NeoX (20B)
base lines
- FT-W(Fine-tuning with weight decay)
- GPT-J의 21번 layer만을 수정 1만개의 데이터에 대해서 최대 25step까지만 돌림(batch size를 크게 한듯)
- MEND
- hypernetwork-based model editing approach
- ROME
1. Editing 10K Memory (zsRE)

첫번째 실험은 대표적인 데이터셋 zsRE로 진행되었다.(Levy et al., 2017)
각각의 평가 지표는 다른 knowledge editing 논문들과 유사하게 아래 3개의 측면으로 진행하였다.
Efficacy

Paraphrase

Specificity

우선 MEMIT이 가장 우수한 성능을 보여주었고, FT-W이 의외로 다른 baselines 보다 좋은 성능을 보여주었다. 해당 이유에 대해서는 다른 모델들은 각 edit을 연쇄적으로 1만 회나 진행하였지만 Fine-tuning의 경우 묶어서 한번에 적용할 수 있기 때문으로 분석하였다.
score = 셋의 조화평균
2. Counterfact scaling curves
다음은 COUTERFACT 데이터셋을 사용하여 counterfactual information에 대해 실험해 보았다.
problem size n은 1개부터 10000개까지 로그 스케일로 데이터를 증가시키며 실험하였다.
해당 실험에서는 위와 상이한 2가지 metric이 새로 추가되었는데
- Reference Score(RS)
- Generation Entropy(GE)

MEND는 지속적으로 성능이 안 좋았다.
ROME은 적은 수정에서는 MEMIT보다 좋은 모습을 보여주는 지표들이 존재했다.

MEND가 수정할수록 변화되는 점이 적어지며 Specificity가 증가할 것이라고 추정하였지만, 구체적인 이유를 언급하진 않음
1만건의 수정시간에 있어서
MEND는 98초
FT-W는 29분
MEMIT은 7.44 시간
ROME은 12.29시간이 걸렸음
Editing different categories of facts
다음은 다양한 category에 대해 진행해 보았다.
똑같이 COUNTERFACT 데이터를 사용하였고
27개의 categories
각 300개의 case로 구성되어 있다.

(a)변경하는 관계에 따라 난이도가 달랐으며, 예시로 운동선수의 종목을 바꾸는 일이 굉장히 어려운 편에 속하였다.
(b)해당 값들을 Generalization과 Specificity의 trade-off의 관점에서 보더라도 MEMIT이 굉장히 강력한 모습을 보여주었다.

다음은 쉬운 category와 어려운 category를 섞었을 때의 결과값으로, MEMIT은 데이터가 섞였을 때 그 중간에 해당하는 값을 안정적으로 내놓았다.
Conclusion
- MEMIT은 LLM의 특정 layer들을 수정하여 factual memory를 수정하는 방법론이다.
- 다른 방법론에 비해 100배 이상의 사이즈로 실험을 진행하였다.
- relation의 종류에 따라 어려움을 겪는 경우가 존재함을 발견하였다.
- 본 논문은 (s, r, o) 형태로 존재하는 factual memory에 대한 수정만을 다루었다.
'논문리뷰 > Knowledge Editing' 카테고리의 다른 글
| [논문 리뷰] Transformer-Patcher: One Mistake Worth One Neuron (1) | 2024.01.25 |
|---|---|
| [논문 리뷰] Can We Edit Factual Knowledge by In-Context Learning? (1) | 2024.01.25 |
| [논문 리뷰] Fast Model Editing at Scale (1) | 2024.01.25 |