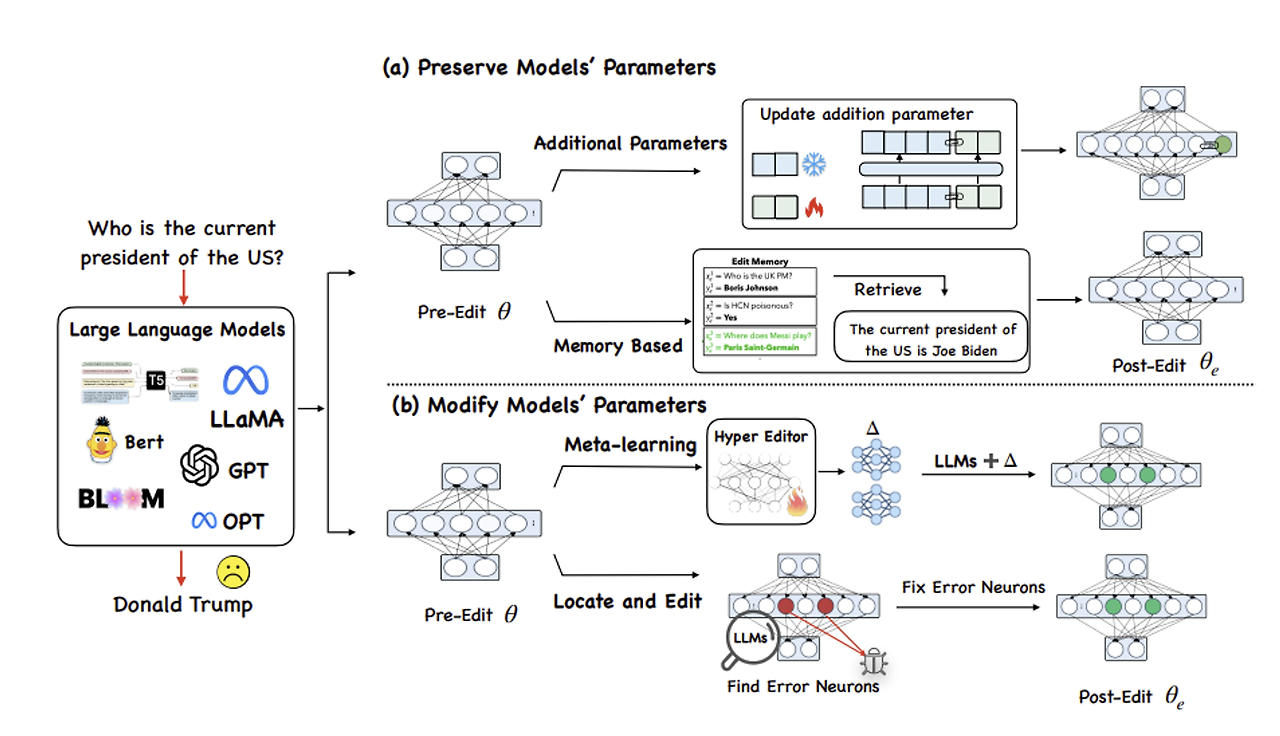
이 글은 체계적인 정리보다는 메모에 가깝습니다. 해당 논문에 대해 이야기 나누고 싶으시다면 언제든지 환영합니다. Mass-Editing Memory In a Transformer Meng et al., 2022 https://arxiv.org/abs/2210.07229 Mass-Editing Memory in a Transformer Recent work has shown exciting promise in updating large language models with new memories, so as to replace obsolete information or add specialized knowledge. However, this line of work is predominantly limite..